Hoa Nguyen

I am pursuing MS degree in Computer Science with a focus on NLP and Deep Learning at the Technical University of Darmstadt, Germany
Previously, I received my Bachelor Degree in Business Information System at the Nuremberg Institute of Technology, Germany
Portfolio
Computer Vision
Emoticon Generation with VAE
![]()
In this project, a VAE-based generative model is implemented that can produce new emojis, resembling those we are familiar with. Moreoever,a latent space interpolation & analysis is also done.

Reconstructed face with VAE
Emotion Recognition with Facial Landmark
![]()
Facial expression can be considered as concrete evidence to identify human feelings.
With the recent advancement in computer vision and deep learning, it is possible to detect emotions from facial images. Facial keypoint detection serves as a basis for Emotional AI application such as analysis of facial expression, detecting dysmorphic facial signs for medical diagnosis. Detecting facial keypoints is a very challenging problem since facial features can vary greately from one individual to another. The primary objective of this project is to predict keypoint positions on image by inspecting different deep learning models based on Convolutional Neural Network.

Machine Learning
Telco Customer Churn
![]()
In this project, we focus on a real application of machine learning in marketing. The dataset we will be using is the Telco dataset available on Kaggle. Our objectives is to find out some interesting statistics about the behavior of our customers and predict some measure that can affect our sales.
Read more »
Software Engineering
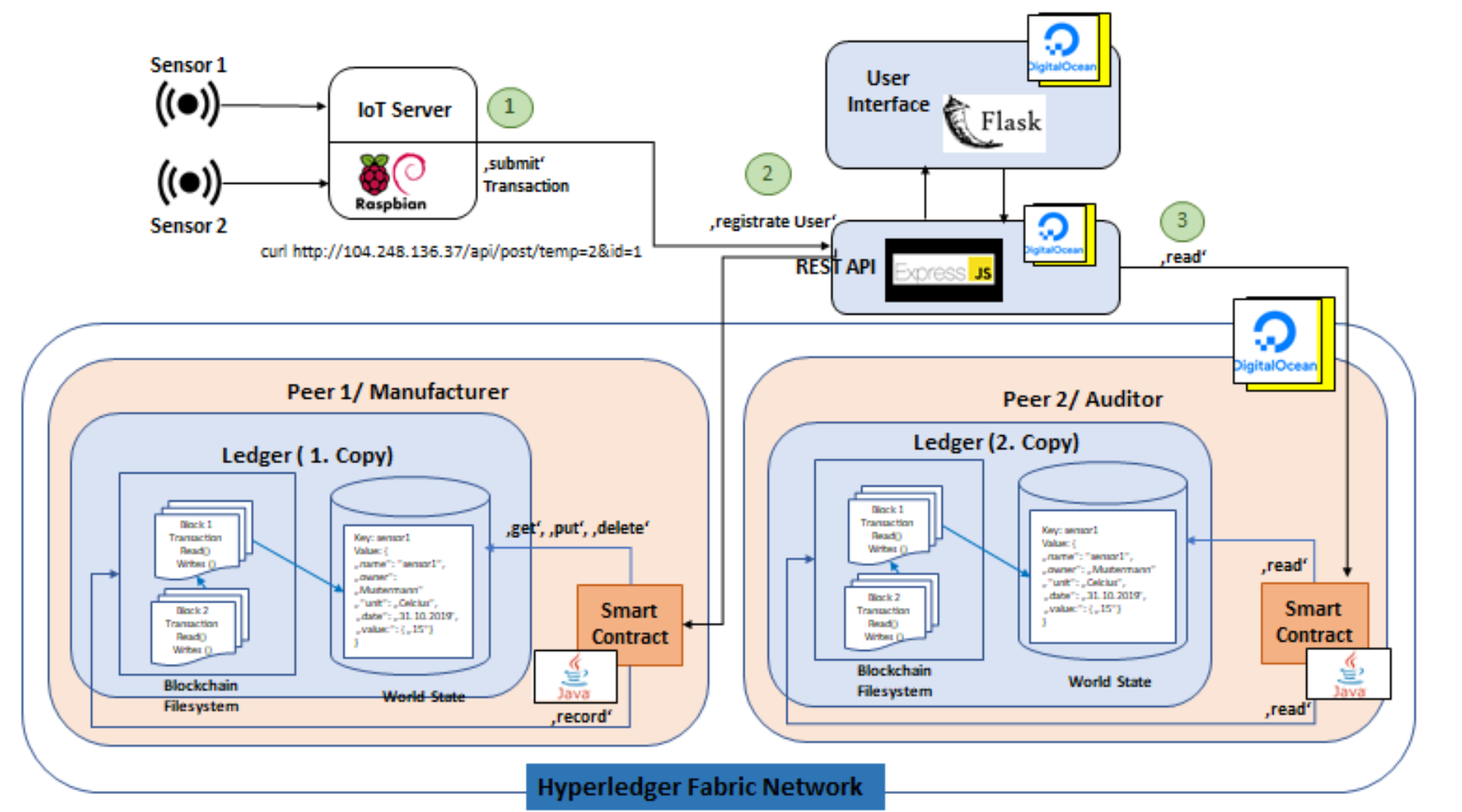
Blockchain
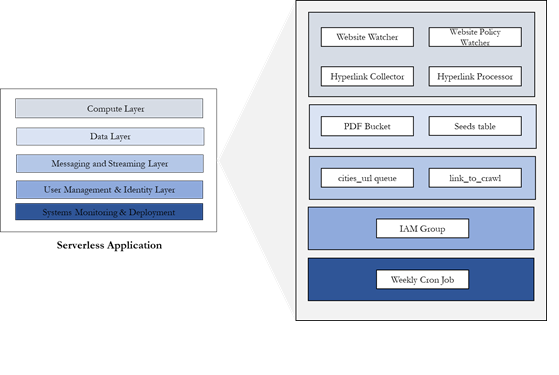
Web Crawling
Natural Language Processing
Twitter Sentiment Analysis with BERT on EU-Solidarity
![]()